TensorFlowチュートリアルモデルを使って、GPU(GeForce GT 1030)とCPU(Core i5-7500 3.4GHz)の学習速度を比較します。
グラボ(GeForce GT 1030)をPCに追加したので、どのくらいDNNの学習速度が向上するのか確認してみました。
比較対象は以下です。
A. GPU(GeForce GT 1030)
B. CPU(Core i5-7500 3.4GHz)
まずはTensorFlowGPU版が動作する環境を構築します。
Windows11に以下をインストールしました。■Microsoft Visual C++ 2015-2022 Redistributable(x64)
対応するアーキテクチャのインストーラをダウンロードして実行します。
■Python 3.10.6
Windows installer(64-bit)をダウンロードして実行します。
■pip 22.2.2
Pythonインストール後、pipコマンドでアップデートします。
pip install --upgrade pip
■tensorflow_gpu-2.9.1
pipコマンドでインストールします。
pip install tensorflow-gpu
■NVIDIA CUDA 11.7
Windows+x86_64+11+exe(network)を選択してインストーラをダウンロードして実行します。
■cuDNN v8.5.0
CUDA 11.7に対応するバージョンをダウンロードします。※アカウント登録が必要
Zipファイルを解凍したあと、CUDAフォルダに上書きします。
CUDAフォルダはデフォルトだと "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7" です。
環境ができたらTensorFlow公式のチュートリアルで実行してみます。
mnistデータセットを使用した10画像分類です。
以下のスクリプトをtest.pyとして保存します。
import os
# https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#env-vars
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
import tensorflow as tf
mnist = tf.keras.datasets.mnist
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(optimizer='adam',
loss=loss_fn,
metrics=['accuracy'])
model.compile(optimizer='adam',
loss=loss_fn,
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test, verbose=2)
model.evaluate(x_test, y_test, verbose=2)
実行してみます。
python test.py
Aの実行結果はこちらです。
2022-08-12 13:28:30.880159: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-08-12 13:28:31.441109: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 1334 MB memory: -> device: 0, name: NVIDIA GeForce GT 1030, pci bus id: 0000:01:00.0, compute capability: 6.1
Epoch 1/5
1875/1875 [==============================] - 5s 2ms/step - loss: 1.5812 - accuracy: 0.8982
Epoch 2/5
1875/1875 [==============================] - 4s 2ms/step - loss: 1.5225 - accuracy: 0.9447
Epoch 3/5
1875/1875 [==============================] - 4s 2ms/step - loss: 1.5090 - accuracy: 0.9561
Epoch 4/5
1875/1875 [==============================] - 4s 2ms/step - loss: 1.5011 - accuracy: 0.9635
Epoch 5/5
1875/1875 [==============================] - 4s 2ms/step - loss: 1.4957 - accuracy: 0.9681
313/313 - 1s - loss: 1.4929 - accuracy: 0.9695 - 562ms/epoch - 2ms/step
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-08-12 13:28:31.441109: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 1334 MB memory: -> device: 0, name: NVIDIA GeForce GT 1030, pci bus id: 0000:01:00.0, compute capability: 6.1
Epoch 1/5
1875/1875 [==============================] - 5s 2ms/step - loss: 1.5812 - accuracy: 0.8982
Epoch 2/5
1875/1875 [==============================] - 4s 2ms/step - loss: 1.5225 - accuracy: 0.9447
Epoch 3/5
1875/1875 [==============================] - 4s 2ms/step - loss: 1.5090 - accuracy: 0.9561
Epoch 4/5
1875/1875 [==============================] - 4s 2ms/step - loss: 1.5011 - accuracy: 0.9635
Epoch 5/5
1875/1875 [==============================] - 4s 2ms/step - loss: 1.4957 - accuracy: 0.9681
313/313 - 1s - loss: 1.4929 - accuracy: 0.9695 - 562ms/epoch - 2ms/step
GPU(GeForce GT 1030) を使用した場合の1エポックあたりの学習時間は平均4.2秒でした。
次はGPUを使用しないで、CPU(Core i5-7500 3.4GHz)で実行してみます。
先ほどはGPUを "PCI_BUS_ID" 順に並べて(CUDA_DEVICE_ORDER)、"0" 番目を使用する指定となっていました。
CPUを使用したいため、存在しない "-1" 番目を指定します。
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
Bの実行結果はこちらです。
2022-08-12 13:29:43.894471: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
2022-08-12 13:29:43.897745: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:169] retrieving CUDA diagnostic information for host: DESKTOP
2022-08-12 13:29:43.897918: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:176] hostname: DESKTOP
2022-08-12 13:29:43.898277: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Epoch 1/5
1875/1875 [==============================] - 3s 1ms/step - loss: 1.5805 - accuracy: 0.8991
Epoch 2/5
1875/1875 [==============================] - 2s 1ms/step - loss: 1.5218 - accuracy: 0.9455
Epoch 3/5
1875/1875 [==============================] - 2s 1ms/step - loss: 1.5087 - accuracy: 0.9567
Epoch 4/5
1875/1875 [==============================] - 2s 1ms/step - loss: 1.5022 - accuracy: 0.9625
Epoch 5/5
1875/1875 [==============================] - 2s 1ms/step - loss: 1.4968 - accuracy: 0.9666
313/313 - 0s - loss: 1.4931 - accuracy: 0.9700 - 359ms/epoch - 1ms/step
2022-08-12 13:29:43.897745: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:169] retrieving CUDA diagnostic information for host: DESKTOP
2022-08-12 13:29:43.897918: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:176] hostname: DESKTOP
2022-08-12 13:29:43.898277: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Epoch 1/5
1875/1875 [==============================] - 3s 1ms/step - loss: 1.5805 - accuracy: 0.8991
Epoch 2/5
1875/1875 [==============================] - 2s 1ms/step - loss: 1.5218 - accuracy: 0.9455
Epoch 3/5
1875/1875 [==============================] - 2s 1ms/step - loss: 1.5087 - accuracy: 0.9567
Epoch 4/5
1875/1875 [==============================] - 2s 1ms/step - loss: 1.5022 - accuracy: 0.9625
Epoch 5/5
1875/1875 [==============================] - 2s 1ms/step - loss: 1.4968 - accuracy: 0.9666
313/313 - 0s - loss: 1.4931 - accuracy: 0.9700 - 359ms/epoch - 1ms/step
何ということでしょう!AのGPUよりもBのCPUの方が早いです。
CPUの場合の1エポックあたりの学習時間は平均2.2秒でした。
予想を裏切る結果でしたが安心してください。
チュートリアルの内容はmnistデータセットという28x28ピクセルの非常に小さな画像を使用しています。
つまり1画像あたりの計算量が非常に少ないのでこのような結果になっていると考えられます。
GPUの方が早い(並行処理できる)ということを証明するために、計算量を多くしてみます。
中間層の以下の部分がノード数の指定です。ここを調節して計算量を10倍、20倍、30倍に膨らませます。
#tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(1280, activation=tf.nn.relu),
#tf.keras.layers.Dense(2560, activation=tf.nn.relu),
#tf.keras.layers.Dense(3840, activation=tf.nn.relu),
結果は以下になりました。
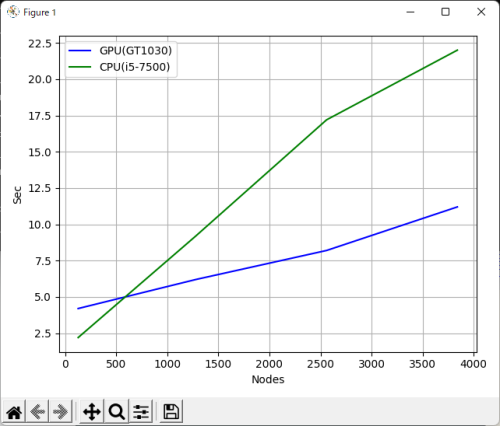
計算量が増えると予想通り、GPUの方が早い(並行処理できる)ということを確認できました。